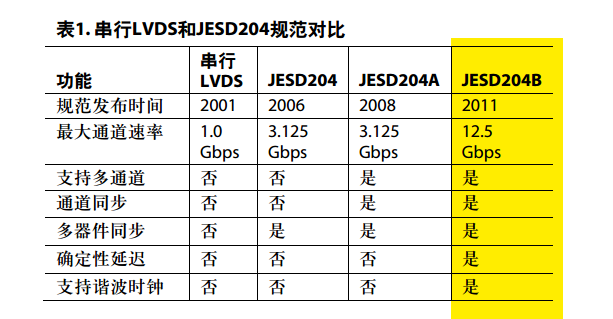
我把204b的标准看下来,感觉链路层在整个204b中是最重要且最复杂的地方,因为是在链路层建立的同步链路,且子类1的确定性延迟也是在这里实现的。
同步链路的建立,也就是确定帧边界与多帧边界,这通过三个阶段来实现————CGS、ILAS和DATA,这在入坑记中已经记录过了,CGS是TX发一堆K28.5字符直到RX将SYNC~解除置位,ILAS是按照规定格式发送四个多帧,最后进入数据阶段。
而关注的确定性延迟就是在CGS至ILAS过渡的地方实现的。
同步链路的三个阶段的具体操作去翻入坑记,这里我重新梳理下确定性延迟的实现。