背景了解
在知乎上看见的专栏写得挺清楚的
内存系列一:快速读懂内存条标签
内存系列二:深入理解硬件原理
需要注意的是,层级关系是channel>DIMM>rank>chip>bank>row/column,是由多个chip组成了一个rank,每个chip数据宽度8bit,那么64bit数据宽度由8个chip级联组成,每个chip再划分为bank,往下就是最小单位rou/colum,具体可参考图解RAM结构与原理。
存储器接口
Xilinx 7Series FPGA的存储器接口示意图如下: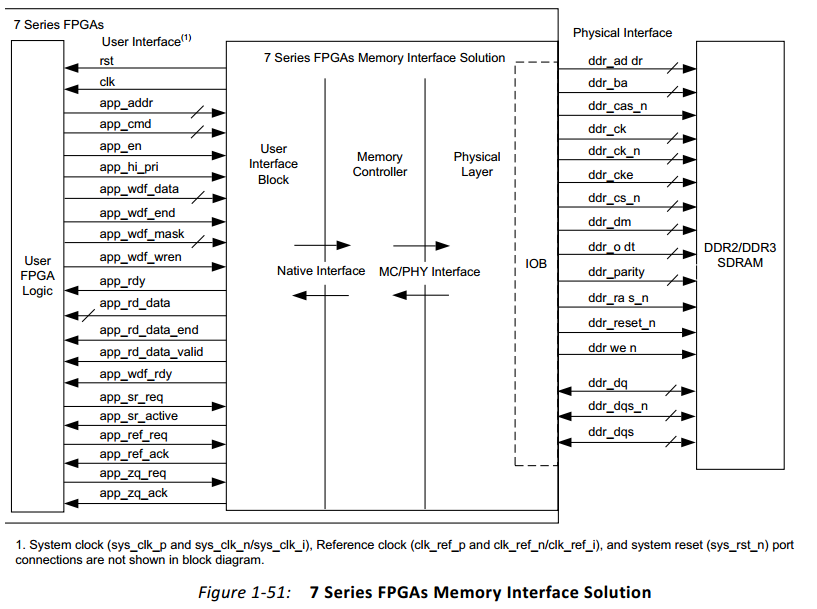
详细的接口定义在UG586_P92。
用户接口
用户接口包括了命令路径、写路径和读路径等,每条路径的信号定义套路好像差不多。
Command Path
命令路径包括app_en,app_addr和app_cmd。
在每个app_en和app_rdy有效的时钟上升沿,产生一次app_cmd对应的有效命令。
app_cmd=0为写入命令,1为读出命令。
app_addr为用户地址,按照设定的映射关系对应至RANK、BANK、ROW和COL,每一个地址对应的数据大小等于ddr_dq位宽,即DDRSRAM的数据位宽。因此在BL8读写时,每次读写时地址值应该加8。
其时序如下图。注意若app_rdy没有置位,app_en & addr & cmd需要保持直到app_rdy有效。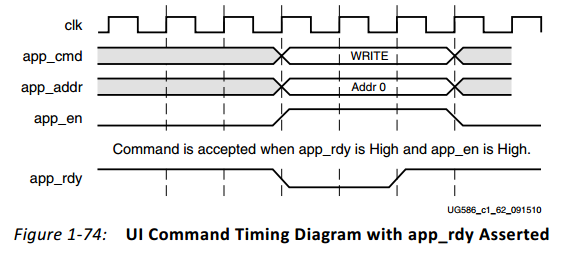
Write Path
写入路径是一个写入fifo接口,且该接口时序不需要和命令路径完全对齐,写入数据可以超前于命令,也可以滞后于命令。唯一条件是对于每个app_cmd写命令,要有相关的app_wdf_data数据呈现。
需要注意数据滞后于命令时最大延迟为2个时钟。另外app_wdf_en和app_wdf_rdy的处理方式和命令路径套路一样。
非背靠背写入数据时序如下图: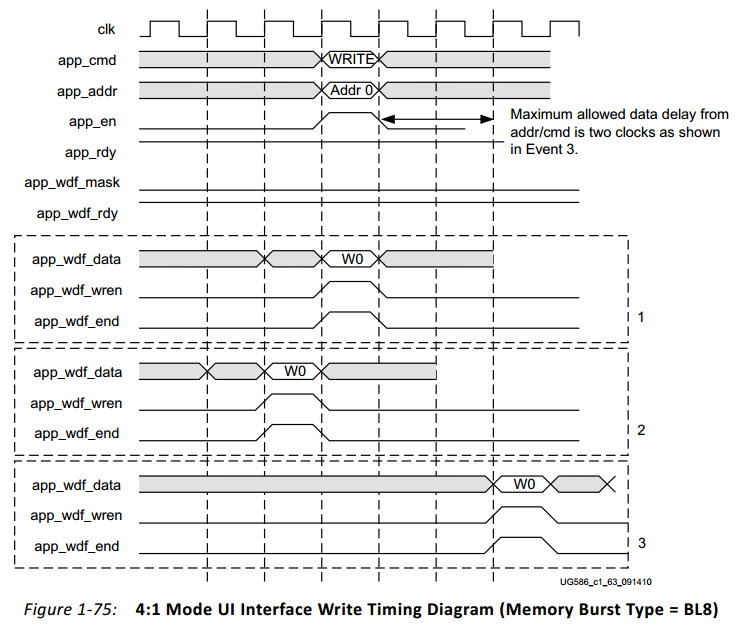
datasheet还给出了突发模式写入的示意图,下图是突发长度8(BL8,即连续写8个地址的数据)的传输,2:1的PHY to Memory Controller clk比例,8bit存储器数据宽度。
首先计算一下,UI数据宽度=822=32bit,即突发长度为4,要实现BL8则需要两个时钟的数据。
从图中可以看到,app_wdf_end(used to indicate the end of a memory write burst)在第二个app_wdf_data有效,即每次突发写对应两个数据长度,与刚才的计算结果一致。
app_en和app_rdy有效长度四个时钟,且app_cmd=0,即有这样相同的4条写指令。app_addr递增的值8与突发写长度8一致。
注意最后一个写指令(app_addr=0000418)与数据app_wdf_data刚好相差两个时钟,满足时序要求。
注意 datasheet中明确说明了Burst Lenth仅支持LB8,即在4:1模式下,一个写入指令对应一次BL8写,那么app_wdf_end信号与app_wdf_en信号应该是同时有效的。
开始仿真的时候没有注意到这个点,以为一次写入指令可以写不限长度的数据进去,费了我好多时间啊…
Read Path
读路径的时序如下图,只需在app_rdy有效和app_en置位时,将app_addr连续的呈出即可。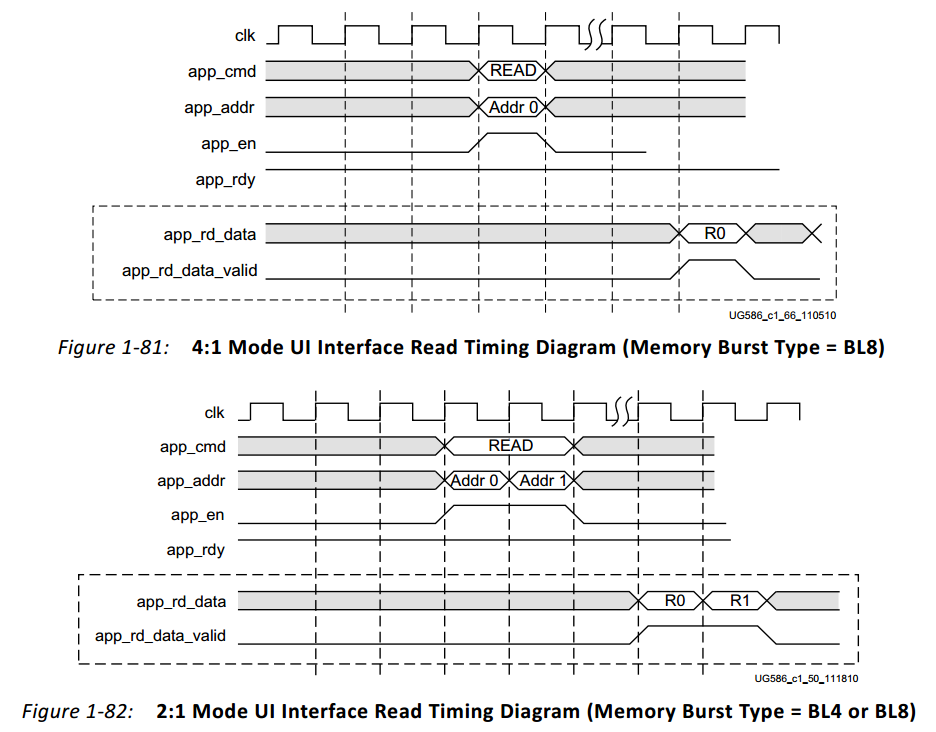
UI接口中还有app_rd_data_end,在用户逻辑中不需要使用。
仿真的时候发现一个细节,除了app_rd_data_valid上升沿的位置,app_rd_data的变化沿相对时钟上升沿有延迟,大约为0.1ns,我因为在比较读出数据时使用了组合逻辑发现了这个细节,所以对读出数据操作时要使用时序逻辑。
仿真
首先写了一个粗糙的仿真验证控制时序,没有采用fifo传递数据给DDR_UI,而是直接传递了一些自定义参数在内部生成的数据,当然实际上不应该这样做,这里只是仿一下时序。正常使用时应该用fifo传递并转换数据宽度。
为了减少控制的麻烦,写路径将app_wdf_wren与app_cmd直接绑定在了一起,也就是写数据始终与写命令同步。
从仿真图中可以看到,app_rdy会出现长段的无效状态,它对连续读写时的控制很重要。
我采取的方法是将app_rdy和app_wdf_rdy一起作为cmd_valid信号控制写操作,当cmd_valid无效时保持当前值直至其有效。
下图是写时序的仿真结果。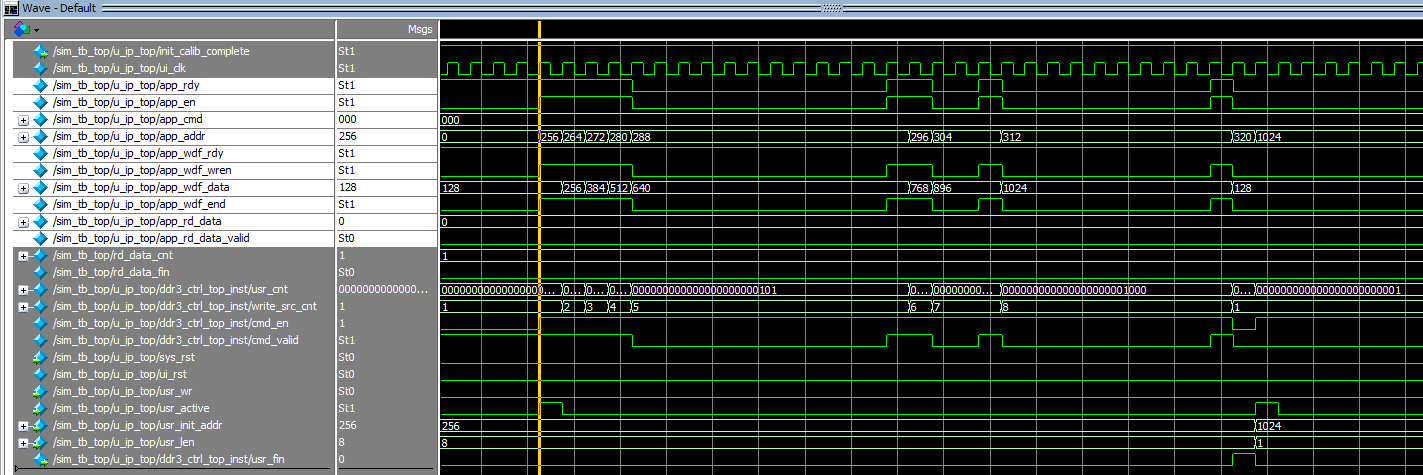
下图是连续写的仿真结果。
从仿真结果可以看到app_rdy会呈周期性地出现无效状态,这应该是DDRSRAM进行刷新等操作带来的,由此影响了写入的效率继而影响连续写入速度。下一步上板实际测试写入速度。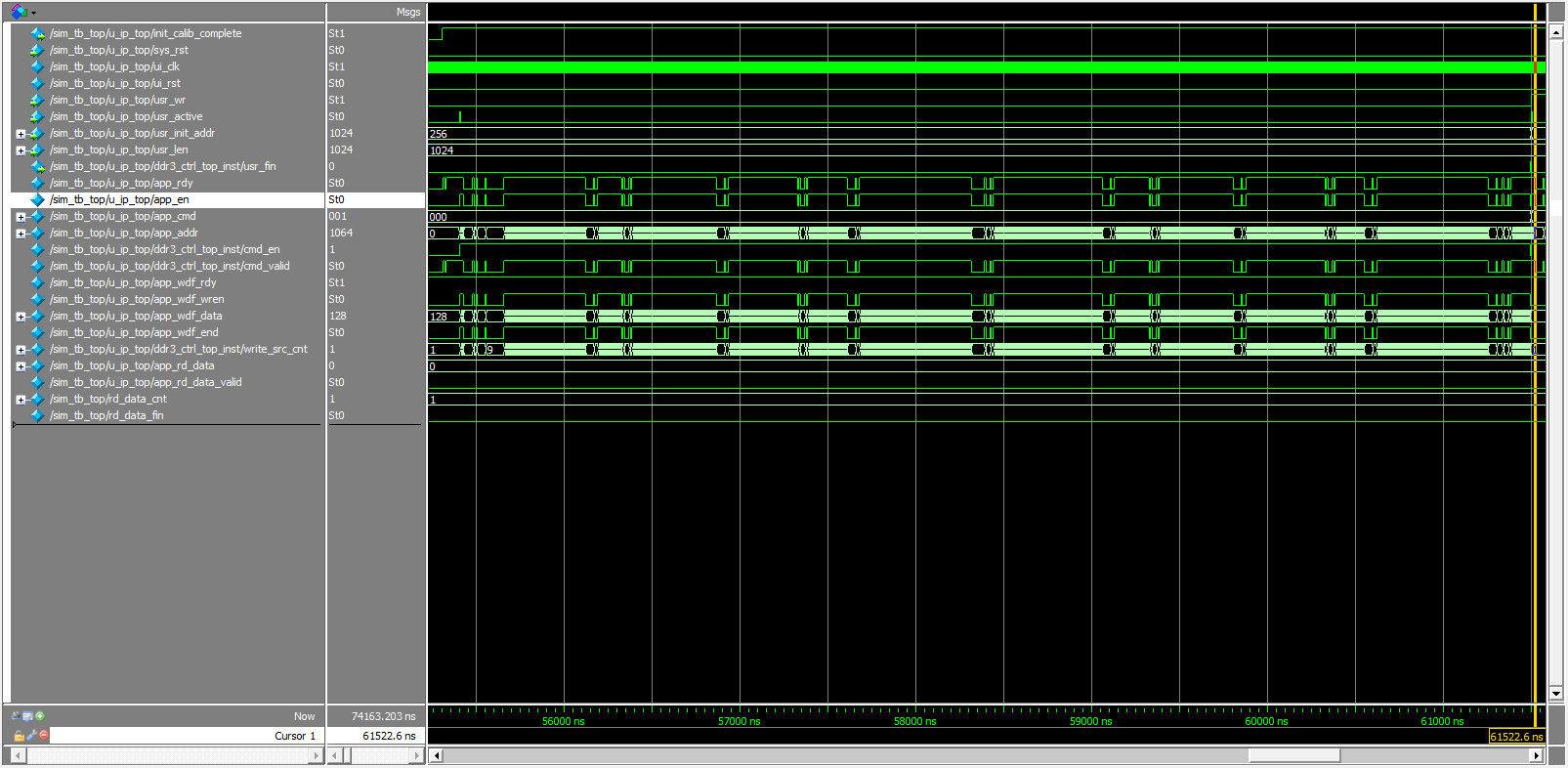
读路径的控制时序则分为两部分,首先是写入命令,然后是接收数据,这之间有一段延时。
下图是读时序仿真结果。与之前写入的值是一致的,说明仿真正确。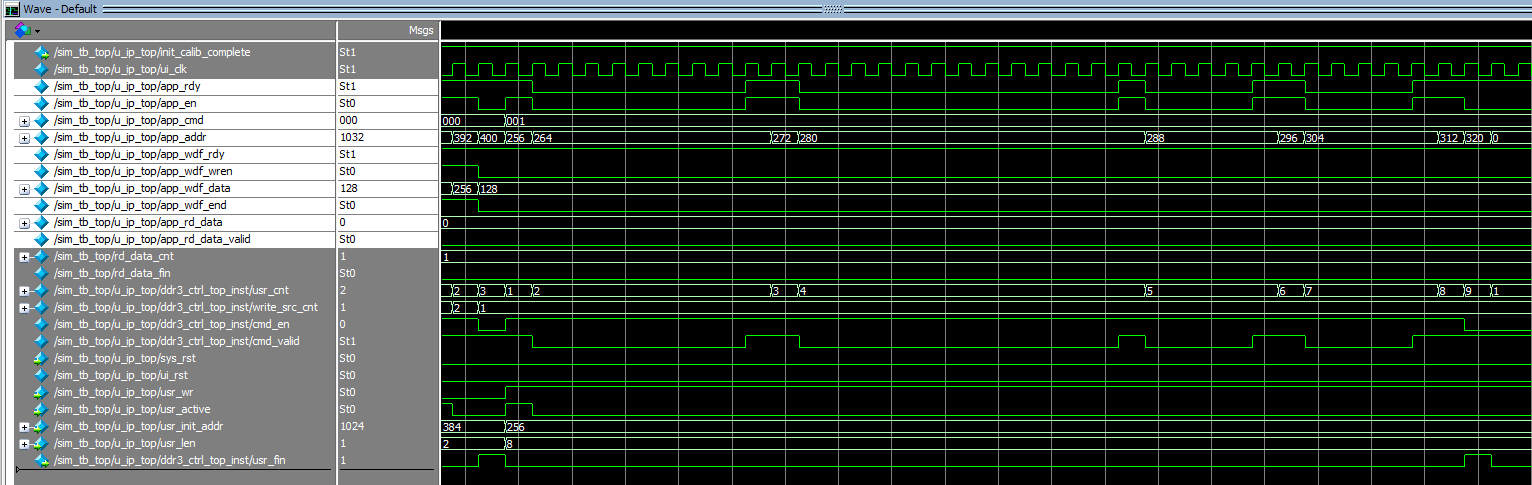
(读仿真写入命令时,app_addr在app_en无效后还递增了一个值,反正不影响,我就没改了… )
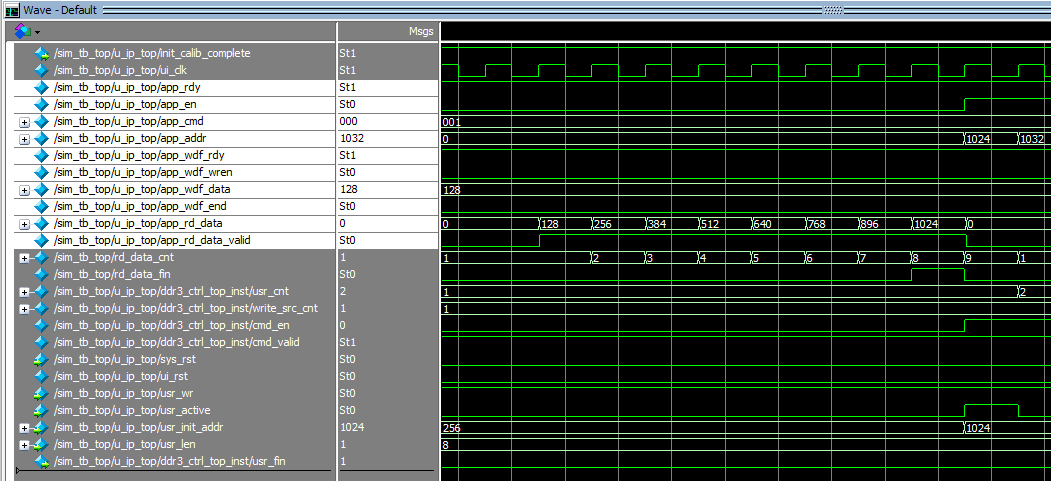
下图是连续读的仿真结果。
app_rdy无效状态的出现与写入时差不多,需要注意在未完全读结束之前app_rd_data_valid也会出现无效状态,因此用户需要在读出时自行计数读出的深度。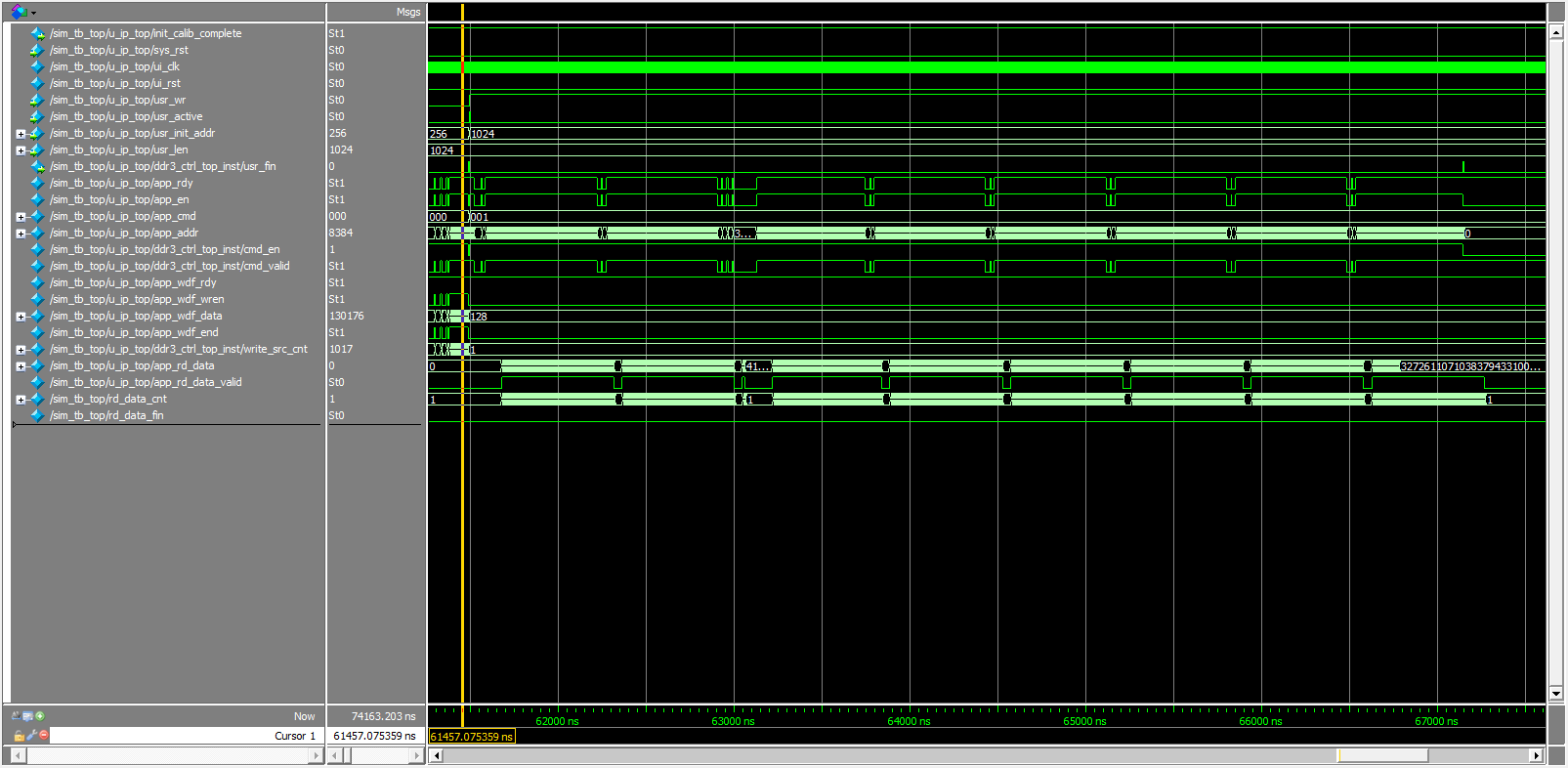
上板测试
使用Xilinx的KC705开发板测试,板卡上的SODIMM大小为1GB,对应用户地址app_addr宽度27bit(每一个地址对应64bit数据),即地址范围0x000_0000~0x7ff_ffff。
工作参数:用户时钟ui_clk 200MHz;DDR工作时钟800MHz;数据位宽64bit。
分别测试写入和读出消耗的时钟周期,测试结果如下图: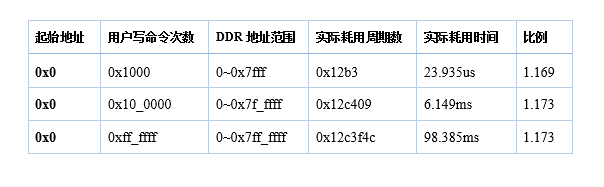
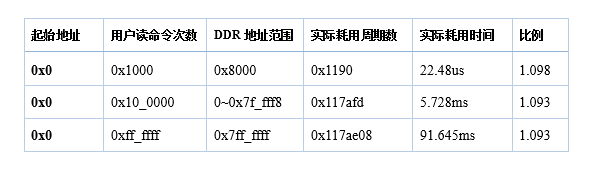
由此可以计算实际大致的写入速度 = 800M * 2 * 64bit / 1.17 = 1600M * 8Byte / 1.17 = 10940MB/s,大约10GB/s的速度,感觉好厉害的样子…
同样的读出速度 = 1600M * 8Byte / 1.1 = 11636MB/s, 大约11GB/s,比写入速度快一些。
不过我想这个读写速度与存储颗粒/条本身的质量关系很大,这个测试数据也就做个参考,之后在项目中用反正是妥妥地速度够用了。
遗留问题
在使用vivado生成DDR IP核的时候,遇到了兼容性问题,生成IP核程序会不定期地卡死,每次打开都是小心翼翼地修改,感觉就是拼运气。而且在导入管脚定义一步时只要一点导入IP核就会跪掉,也是无语…
在网上搜寻一番,有人认为是win10兼容性问题,win7下不会有该问题,但是我没去虚拟机下测试了,直接用example design中生成好的IP拿来用。
但是在官方示例工程基础上写好了测试模块后,上板测试时发现初始化校验不能通过,init_calib_complete信号始终没有拉高。检查了IP核设置和约束等,没有发现任何可能的问题,最终移植了一个老师以前调试好的工程中IP核就可以正常通过了,但还是没发现设置或约束上不同的地方,只能当做遗留问题处理了,以后再开发的时候也就直接移植过来用…
Reference
UG-586-Zynq-7000 All Programmable SoC and 7 Series Devices Memory Interface Solutions v4.2 User Guide 接口相关的在Ch1-Interfacing to the Core-User Interface